



我们认为您会喜欢的其他资源
Siemon 处于 GenAI 革命的前沿,通过与我们的客户和合作伙伴(他们处于提供这些技术的最前沿)合作,我们开发了一系列下一代 AI-Ready 解决方案,可随时为您的部署提供支持。
多年来,人工智能(AI)和机器学习(ML)重塑了各行各业,增强了人们的生活能力,并解决了复杂的全球性问题。这些以前被称为 HPC(高性能计算)的变革力量推动了各种规模组织的数字化转型,提高了生产力、效率和解决问题的能力。
由深度学习和神经网络驱动的高度创新的生成式人工智能(GenAI)模型的出现,正在进一步颠覆游戏规则。这些数据和计算密集型 ML 和 GenAI 应用的使用增加,对数据中心基础设施提出了前所未有的要求,需要可靠的高带宽、低延迟数据传输、显著提高布线和机架功率密度以及先进的冷却方法。
随着数据中心为 GenAI 做好准备,用户需要创新、强大的网络基础设施解决方案,帮助他们轻松设计、部署和扩展后端、前端和存储网络结构,以适应复杂的高性能计算 (HPC) AI 环境。
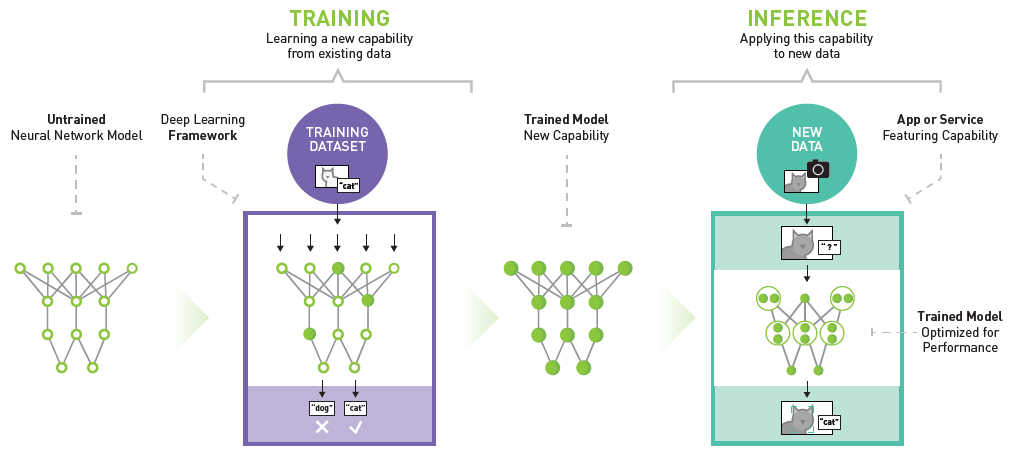
英伟达™(NVIDIA®)深度学习推理平台示例
加速 GenAI 和 ML 模型由训练(学习新功能)和推理(将功能应用于新数据)组成。这些深度学习和神经网络模仿人脑的架构和功能,在分析大量复杂数据集的模式、细微差别和特征的基础上,学习和生成新的原创内容。大型语言模型(LLM),如 ChatGPT 和 Google Bard,就是这些 GenAI 模型的例子,这些模型在海量数据的基础上进行训练,以理解和生成可信的语言反应。按顺序执行控制和输入/输出操作的通用 CPU 无法有效地从各种来源并行提取大量数据,也无法足够快地处理这些数据。
因此,加速 ML 和 GenAI 模型依赖于图形处理器(GPU),GPU 使用加速并行处理来同时执行数千次高吞吐量计算。单个基于 GPU 的服务器的计算能力可媲美数十个传统 CPU 服务器的性能!

